The Promise of Distributed Optimization in Software Development
Introduction
It’s no secret I’ve been working on something cool and unexpected, with a big release announcement coming very soon. However during the course of development I stumbled upon a pattern which I think could provide huge dividends for the emulation community, and is very straightforward to implement.
TLDR;
A full development environment, agentic performance improvement harness, and control plane is just a click away for the average user. How far can we push our open-source projects now that truly anyone can contribute? What if every game, every function, every aspect of our software was being continually optimized by each user, in a distributed fashion?
Building The Flow
Each part of this flow came from an actual need during development of the Playstation 1 port of Johnny Castaway. That means you can go over and try this today, and I’ve had it successfully working for many months.
- An Execution Harness: You need some way to continually execute experiments. For me that was a claude or codex loop, Dunking Bird (obviously before the /goal feature dropped), running headless on a server in my closet. This could be a human, but the point of this article is that everyone can now do this, not just those of us professionally trained to do so.
- A Reasoning Engine: You need a way to reason about the code, postulate improvements, and execute those improvements within code. Again for me this was claude, codex, ds4, etc.
- A Centralized Log: Github or any distributed version control system. You need a log of ideas, a log of successful experiments, and a log of failed experiments.
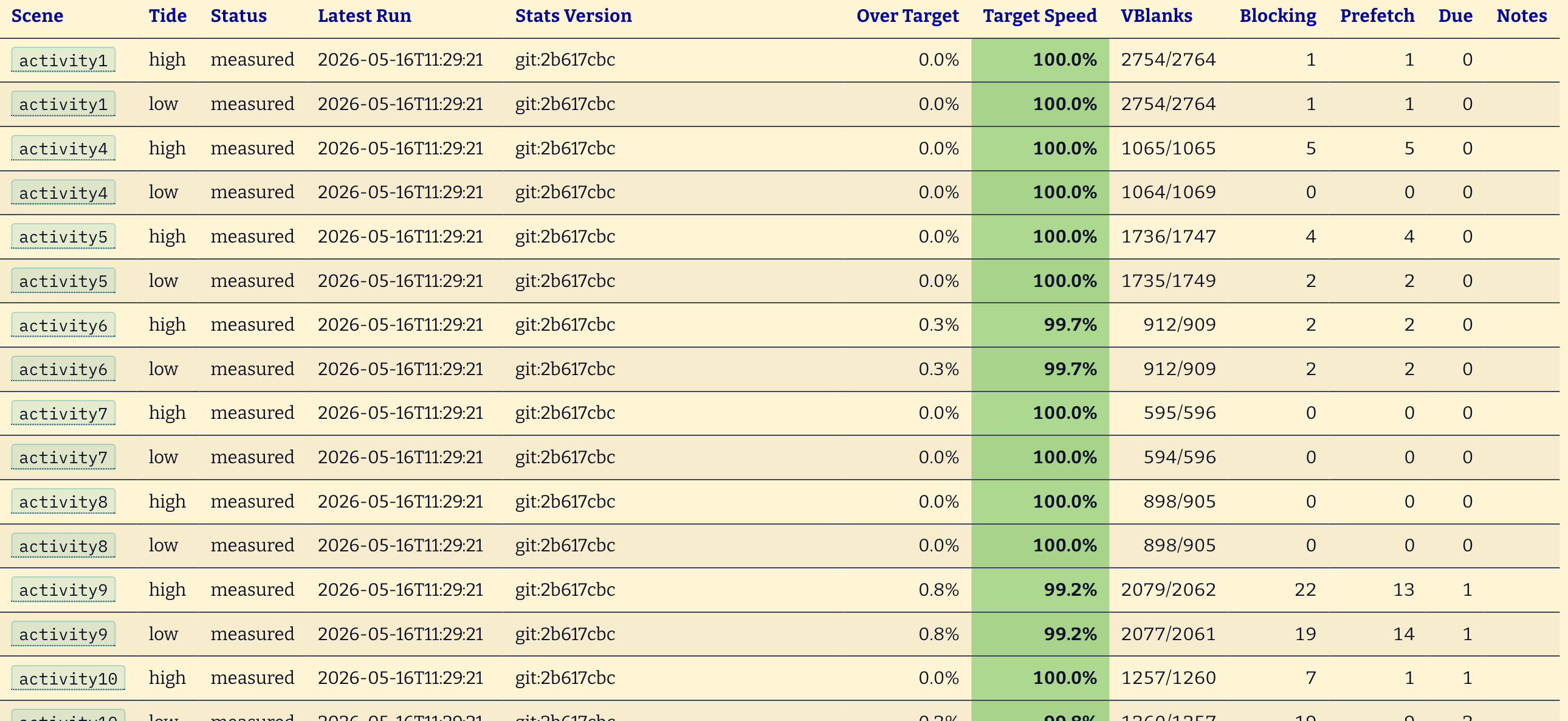
- A Regression Suite: You need some way to regress performance or ground truth against your experiment. Deep performance logging. For Johnny, that was deep performance timing measurement emitted from a known-good port to x86 systems.
- A Finite, Decomposable Problem Set: Finally, you need a problem set or software architecture that’s decomposable. Otherwise you’ll waste effort with everyone re-implementing the same area as folks work to improve the system in parallel. Johnny had 127 unique scenes, each with its own memory profile and asset usage. I suppose it’s not a strict requirement but I’m saying this technique is for ‘problem sets’
Simple parts coming together to deliver on one of the central promises of open source: that everyone can improve software together. For the port I’ve been working on, you can have a new node up and running in a few minutes with any off-the-shelf agentic model. Perf testing, improvement looping, dockerized headless runs, dockerized cross-compiler and iso builder. Anyone can run, and anyone can contribute.
An agent in an infinite refinement loop regressing against micro-optimizations in code and technique using headless docker containers.
All of this runs on an old surface laptop (quite beat up, bought at thrift store), running KDE Neon, remote desktop’d in from my laptops/tablets/etc. A single node in an ever-growing distributed system, each node doing it’s part to improve the system.
It feels incredibly futuristic, and stupid simple at the same time. In the past month using this technique I’ve taken speed from 70% to 99.8% average in an incredibly difficult port with little to no headroom. Thousands of tiny improvements stacking on each other for real gains.
The Realness
There’s some AI slop/crap in the code still. Certainly there’s a lot of cleanup I can do, it’s not a particularly clean codebase. It’s not great for pedagogy, or human maintainability. Those are open, hard problems I’m working to solve. What it is, is working well. It’s the impossible port I didn’t have enough time to get working at full speed on my own. As I take a step back and start to prepare for a version 1 release, I realize it’s a prototype for a paradigm that threads through my entire career. Distributed computing. Open source. Optimization. Bringing new ability to the non-technical contributor.
I think back to high school, 30+ years ago. How I looked in awe upon the game developers who released their code, the very early emulator developers who seemed to do impossible things. I wanted to help, to be a part of it. Those are some of the feelings that drove me into a career in computer science, into who I am today. Would I still have taken that path today if there was an ‘easy button’ to contribution? Maybe. Probably. But that’s not the problem I’m out here trying to solve, that’s not the world I’m out here dreaming in public.
Bringing it all together for Emulation
There are trends in our industry that seem to be converging, and that ever-present nebula will soon fold into a black hole in my mind. It’s hard to divorce my thinking from the reality of the world we’re in today. Memory shortages are driving the price of memory sky-high and the specs on the average computing device have started to fall. The MacBook Neo launched to great acclaim with 8gb of RAM. At the same time frontier models have continued to climb in capacity, currently meeting or exceeding the performance of the average junior to mid-level engineer.
All the while, I think about performance. I’m very much aligned with John Carmack: the world could run our current software on hardware that’s an order of magnitude less powerful if we actually cared about performance optimization.
And there’s the wind-up. Now imagine you’re, say, an emulator developer. You don’t want to deal with a billion incoming pull requests, AI slop, noise, constant stress. So you carve off something. Maybe it’s a per-game setting of some sort. Maybe you’re trying to do something a little ridiculous. So you say (much as I did), that there’s a huge amount of opportunity in custom compression/decompression algorithms, and in saving decoding time. So you open it up, each game has it’s own configuration file detailing compression and decompression schemes and their implementation, maybe pre-compiled and loaded statically at runtime. Doesn’t matter.
Now every user who can afford 10$/mo in Deepseek usage can contribute. What percentage of your audience would contribute knowing that it’s just a button press away? I as one node was able to implement thousands of micro-improvements over 120 scene variants in a couple of months. With 100 users doing the same it would have taken days. What could 1000 do? A million? How far could we push even a single optimization path with a billion experiments?
What can we do when the barrier to entry is effectively zero? (admitting that there have been times that 10$/mo felt like an infinite amount, and recognizing my current privilege to be able to say so.) Knowing projects can be structured in this way today, I’m emboldened.
The Desktop
Here’s a screenshot of the workflow in action:
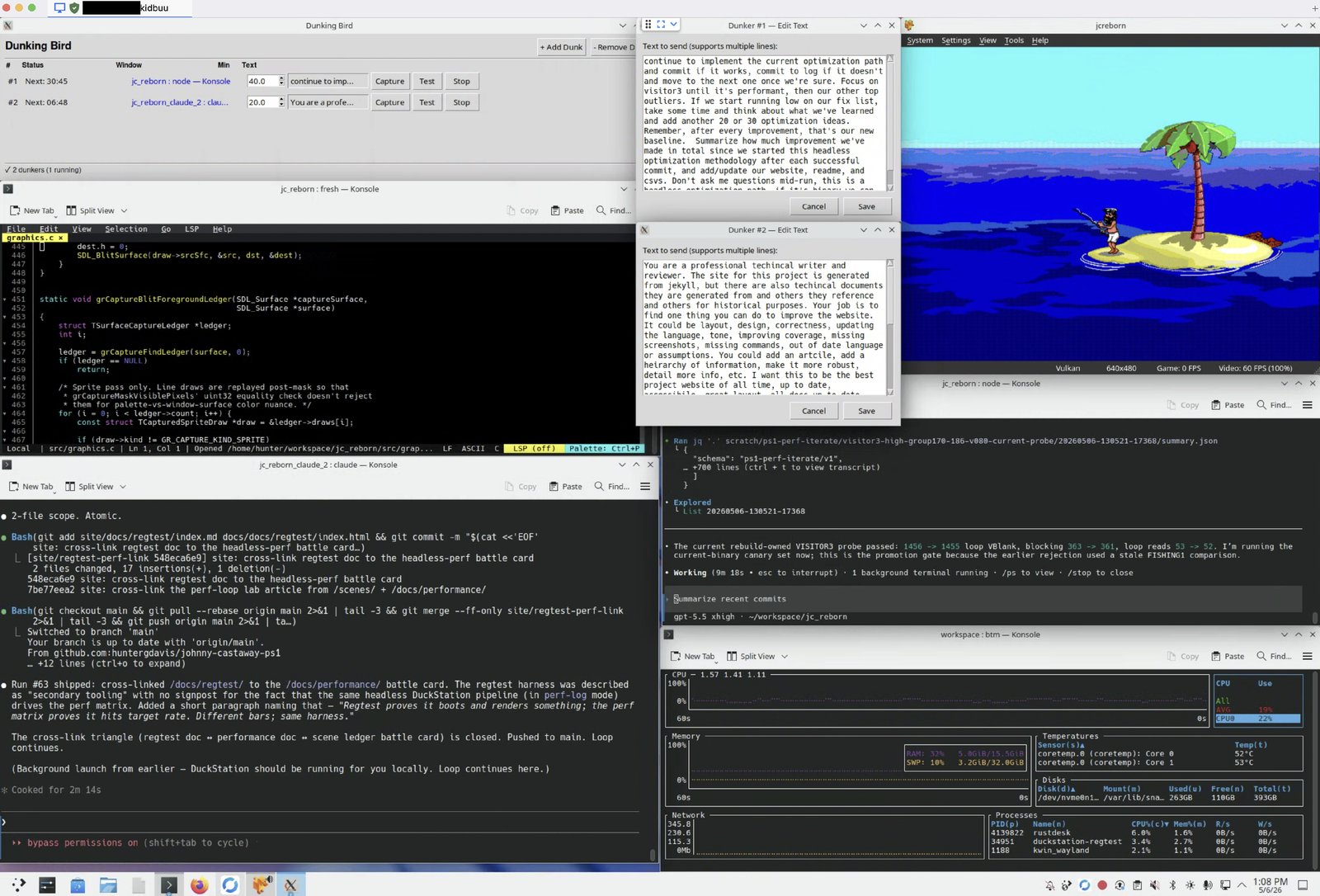
{kind=link}
A Simple Distributed Optimization Template For My Next Project
- However it’s built, that must happen in docker from day 1.
- However it runs, it must be able to run headlessly, preferably in docker.
- Wherever the source is stored, it must be in a distributed fashion, and contain 4 logs: performance targets vs current, improvements, successful experiments, failed experiments.
- Whatever it does, there should be clear performance measurement and targets, stored within the source.
- Whatever those targets are, they should be distinct and decomposable.
Try It Out
GitHub Repository: You can find the complete source code, installation instructions, and documentation on GitHub: huntergdavis/johnny-castaway-ps1
Project Website: You can find all the above, and some interesting write-ups (and some AI crap) on the official project website. hunterdavis.com/johnny-castaway-ps1
Finally
I’d love to hear if anyone else has tried this (very similar concept to autoresearch.)